
Data Structures in Programming form the backbone of software efficiency, shaping how data is stored, accessed, and optimized for speed and scalability. By understanding core concepts of data structures, developers can choose structures that balance time and space, enabling faster searches, insertions, and updates. This introduction highlights how different types of data structures meet real-world data structure use cases, from quick lookups to long-running queueing tasks. From arrays and linked lists to trees, graphs, and hash tables, these tools help you design robust, high-performance systems. As you read, you’ll see how choosing data structures for applications shapes both code quality and system behavior.
Viewed through an alternative lens, these ideas are about how information is organized, stored efficiently, and retrieved on demand. In LSI terms, you’ll hear references to data organization structures, collection types, and indexing strategies that map to arrays, lists, trees, graphs, and maps. This framing helps you spot equivalent patterns across technologies and languages, guiding you toward the right choice for a given workload. By aligning design decisions with practical use cases—such as fast lookups, dynamic growth, or durable on-disk storage—you can translate theory into reliable, scalable software.
Data Structures in Programming: Core Concepts, Types, and Real-World Use Cases
Data Structures in Programming are the building blocks that shape how software stores and processes information. In this section we cover the core concepts of data structures: how data is stored, how it is accessed, and how common operations—insert, delete, search, and update—perform under different circumstances. By framing these ideas through time and space complexity (Big-O), you learn to compare alternatives and weigh trade-offs between speed, memory usage, and safety. Understanding mutable versus immutable storage helps you design for performance in everything from quick scripts to concurrent systems, where predictability matters as much as raw speed. This is the foundation of making software efficient and reliable.
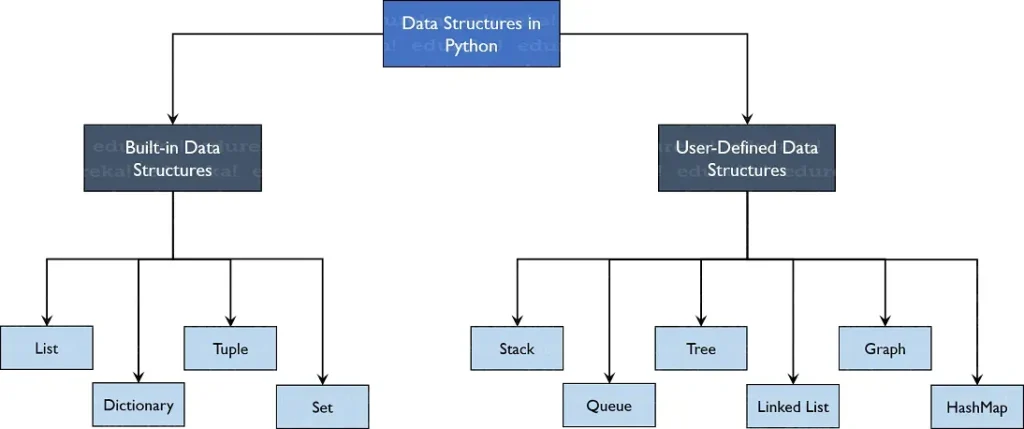
Beyond theory, consider the broad categories—arrays, linked lists, stacks, queues, trees, graphs, hash tables, heaps, and tries—and how their properties map to real tasks. Each type has its own strengths, trade-offs, and best-fit use cases. For example, arrays offer fast index-based access but fixed capacity; hash tables deliver rapid lookups with collisions needing careful handling; trees and graphs enable hierarchical and networked models; tries boost prefix search and autocomplete. These are the real-world data structure use cases that drive architectural decisions in databases, search engines, compilers, and streaming pipelines. When you connect specific problems to these categories, choosing the right data structure becomes a matter of aligning workload with the structure’s strengths—an essential skill in data structures in programming.
Choosing Data Structures for Applications: Practical Guidelines from Core Concepts to Real-World Use Cases
Choosing data structures for applications requires a disciplined approach that roots decisions in the dominant operations and growth patterns. Start by identifying the core operations—random access, insertion, deletion, traversal, or search—and then consider data size and growth rate. Weigh time versus space: is latency more important than memory footprint? Do you need concurrency safety or immutability to simplify parallel code? Factor locality of reference to improve cache performance, and plan for domain-specific patterns such as indexing with trees in databases or lookup services with hash maps. This pragmatic guide ties back to the data structures in programming landscape and helps you select tools that scale with user demand.
To translate theory into practice, map your scenario to concrete use cases: a caching layer might rely on hash tables with eviction policies; a file system index uses B-trees or B+-trees; a routing engine employs graphs for pathfinding; a compiler uses abstract syntax trees; a streaming system may use queues and priority queues. This real-world mapping shows how core concepts translate into robust designs. By documenting expected operations, data volumes, and concurrency constraints, you can justify the selection of data structures for applications and maintain clarity for future maintenance and optimization.
Frequently Asked Questions
Data Structures in Programming: What are the core concepts of data structures and how do they influence performance?
In Data Structures in Programming, the core concepts include how data is stored (mutable vs immutable), how it is accessed, and the operations supported (insertion, deletion, retrieval, search, traversal). Time and space complexity (Big-O) guide these decisions. The core concepts of data structures shape performance because different structures optimize different operations: arrays offer fast index-based access but fixed size; linked lists allow dynamic growth; hash tables enable near-constant-time lookups with careful collision handling; trees and graphs model hierarchical and network relationships; heaps support efficient priority ordering. Understanding these trade-offs helps you choose the right structure for a given workload and balance speed with memory usage.
Data Structures in Programming: What are common types of data structures and how can real-world data structure use cases guide choosing data structures for applications?
Common types of data structures include arrays and dynamic arrays, linked lists, stacks, queues, trees, graphs, hash tables, heaps, and specialized forms like tries and suffix trees. Real-world data structure use cases illustrate why these types matter: arrays power fast indexing; tries enable autocomplete and pattern matching; hash tables support caches and dictionaries; B-trees and variants power database indexes; graphs model networks and routing; priority queues drive scheduling. When choosing data structures for applications, assess dominant operations (read/write patterns), data size and growth, time vs. space trade-offs, concurrency and safety requirements, and locality of reference to optimize performance.
| Topic | Key Points | Real-World Notes / Examples |
|---|---|---|
| Core Concepts | Data structures store and organize data, define how data is accessed, and determine how operations (insert, delete, search, update) perform. Big-O notation describes how performance scales with data size. Distinguish mutable vs immutable storage and weigh time/space trade-offs. |
|
| Operations & Complexity | Key operations include insertion, deletion, access/retrieval, search, and traversal. Implementation details (e.g., indexing, pointers) influence performance; consider dominant operations to guide choice. |
|
| Storage Models | Mutable structures allow in-place updates; immutable structures simplify reasoning and concurrency safety. Consider locality of reference and how updates affect memory layout. |
|
| Common Data Structures Overview | Major categories and their strengths: Arrays, Linked Lists, Stacks/Queues, Trees, Graphs, Hash Tables, Heaps, Tries/Suffix Trees. |
|
| Real-World Use Cases | Choosing the right structure shapes performance and reliability in real systems. |
|
| Guidelines for Applications | Practical criteria to pick a structure based on workload and constraints. |
|
Summary
This HTML table summarizes the core ideas around data structures in programming, including core concepts, common structures, real-world use cases, and practical guidelines for selecting appropriate data structures in software design.

